ORC 和 Parquet 文件格式
ORC 和 Parquet 是两种常用的列式存储格式,都支持 schema 定义、索引、压缩等特性,本文分别分析两种文件的格式和实现原理
1. ORC
官方文档
ORC 是一种列式存储格式,文件中不仅保存了数据,还保存了数据的格式和编码信息,以及数据的索引。
1.1 文件格式
如上图所示 ORC 文件由多个 Stripe、一个 Metadata、一个 File Footer 和一个 PostScript 组成
1.1.1 Stripe
Stripe 是 ORC 文件的基本存储单元,每个 Stripe 相互独立,同一行数据只能包含在同一个 Stripe 中。 Stripe 中的数据在逻辑上划分成多个 Row Group,默认每 10000 行数据构成一个 Row Group。Stripe 物理上划分为 Index Streams、Data Streams 和 Footer。
- Stream
message Stream {
// if you add new index stream kinds, you need to make sure to update
// StreamName to ensure it is added to the stripe in the right area
enum Kind {
PRESENT = 0;
DATA = 1;
LENGTH = 2;
DICTIONARY_DATA = 3;
DICTIONARY_COUNT = 4;
SECONDARY = 5;
ROW_INDEX = 6;
BLOOM_FILTER = 7;
BLOOM_FILTER_UTF8 = 8;
// Virtual stream kinds to allocate space for encrypted index and data.
ENCRYPTED_INDEX = 9;
ENCRYPTED_DATA = 10;
// stripe statistics streams
STRIPE_STATISTICS = 100;
// A virtual stream kind that is used for setting the encryption IV.
FILE_STATISTICS = 101;
}
optional Kind kind = 1;
optional uint32 column = 2;
optional uint64 length = 3;
}
Stream 是 ORC 文件中的最小存储单元,Stream 分为多种类型,其中 ROW_INDEX 对应 Row Index,用于存储 Row Group 的统计信息,BLOOM_FILTER 对应 Bloom Filter Index,用于快速判断查询条件是否命中。
- Index Streams
- Row Index
message RowIndex { repeated RowIndexEntry entry = 1; } message RowIndexEntry { repeated uint64 positions = 1 [packed=true]; optional ColumnStatistics statistics = 2; } message ColumnStatistics { optional uint64 numberOfValues = 1; optional IntegerStatistics intStatistics = 2; optional DoubleStatistics doubleStatistics = 3; optional StringStatistics stringStatistics = 4; optional BucketStatistics bucketStatistics = 5; optional DecimalStatistics decimalStatistics = 6; optional DateStatistics dateStatistics = 7; optional BinaryStatistics binaryStatistics = 8; optional TimestampStatistics timestampStatistics = 9; optional bool hasNull = 10; optional uint64 bytesOnDisk = 11; optional CollectionStatistics collectionStatistics = 12; }- Bloom Filter
message BloomFilter { optional uint32 numHashFunctions = 1; repeated fixed64 bitset = 2; optional bytes utf8bitset = 3; } message BloomFilterIndex { repeated BloomFilter bloomFilter = 1; } - Data Streams
实际存储数据的部分,每个 Stream 对应一个 Row Group 的一列数据。 - Stripe Footer
message StripeFooter {
repeated Stream streams = 1;
repeated ColumnEncoding columns = 2;
optional string writerTimezone = 3;
// one for each column encryption variant
repeated StripeEncryptionVariant encryption = 4;
}
message ColumnEncoding {
enum Kind {
DIRECT = 0;
DICTIONARY = 1;
DIRECT_V2 = 2;
DICTIONARY_V2 = 3;
}
optional Kind kind = 1;
optional uint32 dictionarySize = 2;
// The encoding of the bloom filters for this column:
// 0 or missing = none or original
// 1 = ORC-135 (utc for timestamps)
optional uint32 bloomEncoding = 3;
}
message StripeEncryptionVariant {
repeated Stream streams = 1;
repeated ColumnEncoding encoding = 2;
}
记录了:
- Stripe 中各个 Stream 的类型、对应的列、整体长度。
- 每个列的编码方式
- 每个 Stream 中每个列的编码方式
1.1.2 Metadata
message StripeStatistics {
repeated ColumnStatistics colStats = 1;
}
message Metadata {
repeated StripeStatistics stripeStats = 1;
}
Metadata 由各个 Stripe 的列统计信息组成
1.1.3 File Footer
message Footer {
optional uint64 headerLength = 1;
optional uint64 contentLength = 2;
repeated StripeInformation stripes = 3;
repeated Type types = 4;
repeated UserMetadataItem metadata = 5;
optional uint64 numberOfRows = 6;
repeated ColumnStatistics statistics = 7;
optional uint32 rowIndexStride = 8;
// Each implementation that writes ORC files should register for a code
// 0 = ORC Java
// 1 = ORC C++
// 2 = Presto
// 3 = Scritchley Go from https://github.com/scritchley/orc
optional uint32 writer = 9;
// information about the encryption in this file
optional Encryption encryption = 10;
optional CalendarKind calendar = 11;
}
message StripeInformation {
// the global file offset of the start of the stripe
optional uint64 offset = 1;
// the number of bytes of index
optional uint64 indexLength = 2;
// the number of bytes of data
optional uint64 dataLength = 3;
// the number of bytes in the stripe footer
optional uint64 footerLength = 4;
// the number of rows in this stripe
optional uint64 numberOfRows = 5;
// If this is present, the reader should use this value for the encryption
// stripe id for setting the encryption IV. Otherwise, the reader should
// use one larger than the previous stripe's encryptStripeId.
// For unmerged ORC files, the first stripe will use 1 and the rest of the
// stripes won't have it set. For merged files, the stripe information
// will be copied from their original files and thus the first stripe of
// each of the input files will reset it to 1.
// Note that 1 was choosen, because protobuf v3 doesn't serialize
// primitive types that are the default (eg. 0).
optional uint64 encryptStripeId = 6;
// For each encryption variant, the new encrypted local key to use
// until we find a replacement.
repeated bytes encryptedLocalKeys = 7;
}
File Footer 负责记录文件的 metadata :
- Stripe 信息
记录每个 Stripe 的:位置和长度、Index Data 的长度、Row Data 的长度、Stripe Footer 的长度、包含的数据行数 - 列信息
记录每个列的 metadata ,包含:列的数据类型、复合数据类型的子类型列表、列的名字等信息 - 列统计信息
记录每一列的 MAX MIN SUM 等信息,用于查询时谓词下推 - **用户自定义 metadata **
用户自定义的 Key - Value 键值对
1.1.4 PostScript
记录文件的 Footer 长度、Metadata 长度、压缩方式、压缩块大小、文件版本、magic number 等信息
1.2 文件索引
1.2.1 列统计信息 Column Statistics
由文件格式可知 ORC 一共有三级列统计信息:
- 每个 Stripe 内 RowGroup 的列统计信息———— Row Index,即每个 Data Stream 的统计信息
- 每个 Stripe 的列统计信息
- 整个文件的列统计信息
查询时利用各级列统计信息逐级下推,减少不必要的数据扫描。
对所有 primative 类型的列统计信息包括:最大值、最小值,对数值类型还包括总和,对可为 NULL 的类型还包括 hasNull 的布尔值。
1.2.2 Bloom Filter Index
Bloom Filter Index 只存在于 RowGroup 级,即每个 Data Stream 对应一个 Bloom Filter Index,Bloom Filter 更适合精确的点查询。
存储时 Bloom Filter Index 和 Row Index 对应的 Stream 交替保存在一起,读取时一起读取用于快速判断是否需要读取该 Stream。
2.Parquet
官方文档
Thrift 定义
Parquet 也是列式存储格式,同时保存了数据和数据的 metadata 。Parquet 支持数据和 metadata 不保存在同一个文件中,一个 metadata 文件可以对应多个数据文件。
2.1 文件结构
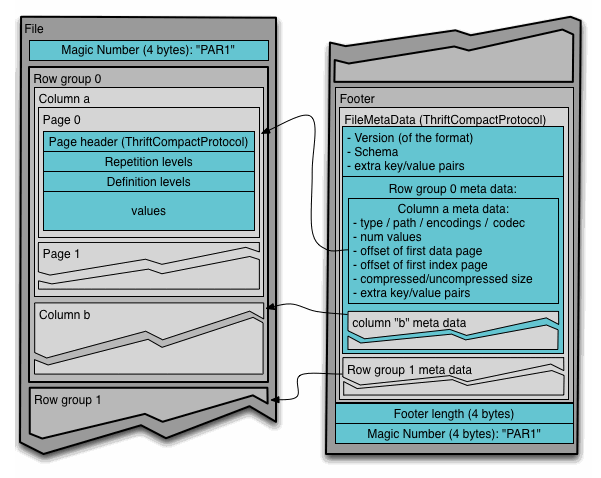
Parquet 文件主要由以下部分组成:
- 文件头的 Magic Number,4 个字节
- 实际保存数据的 Column Chunks
- 文件 Footer,保存文件的 MetaData
- Footer 的长度,4 个字节
- 文件尾的 Magic Number,4 个字节 下面着重分析 Column Chunks 和 Footer 的结构。
2.1.1 Column Chunks
文件的数据部分首先划分成多个 Row Groups
- Row Group
一行数据只存在于一个 Row Group 中,Row Group 推荐的大小在 512MB - 1GB,每个 Row Group 包含每一列的一个 Column Chunk - Column Chunk
一个 Column Chunk 对应一个列,由多个 Pages 组成 - Page
Page 是 Parquet 文件中最小的数据存储单元
- DataPage
保存实际的列数据,由以下部分组成:- Page header
- repetition levels data
- definition levels data
- encoded values 编码后的数据
- DictionaryPage
如果 DataPage 中的数据为字典编码,即将数据的不同 value 保存到一个字典中,DataPage 实际保存 value 在字典中的坐标,则会将编码用的字典保存在 DictionaryPage 中,DictionaryPage 位于所有 DataPage 之前。这适用于不重复值较少的列,比如一些枚举字段,如果不重复的值太多导致字典的大小过大则不推荐使用字典编码,会降级到 plain 编码。 - DataPageV2
新的 DataPage 类型,其 definition levels 和 repetition levels 都是非压缩可以直接读
2.1.2 Index
- Page Index
在旧版本中 ColumnChunk 的列统计信息保存在 ColumnMetaData 中,DataPage 的列统计信息保存在 DataPageHeader 中,这导致在从 DataPages 读取数据时需要扫描每一个 DataPageHeader 来决定是否跳过这个 page,效率很低。因此在 RowGroup Metadata 增加两个列维度的数据结构:- ColumnIndex:记录 page 和 page 的列统计信息
- OffsetIndex:记录 page 在文件中的 offset、压缩后的大小、以及 page 里最小的行号
这两个结构保存在 RowGroup 之后靠近 Footer 的地方,这样如果查询不需要用索引过滤,就可以直接读取 RowGroup 的数据,减少 IO 开销。
利用这两个 Index 可以实现: - 如果查询的过滤条件包含有序的列,可以通过 ColumnIndex 二分查找找到该列满足条件的 page,然后根据 OffsetIndex 中 page 对应的 row index range 过滤其他列的 page,最后只读取满足条件的行。
- 如果查询的过滤条件是无序的列,也可以用 ColumnIndex 过滤掉不满足条件的 page 及这些 page 对应其他列的 page,减少读取的行数。
以一列时间戳和一列 value 为例:
column index for column ts:
Boundary order: UNORDERED
null count min max
page-0 0 2025-04-12T10:00:00.000 2025-04-12T10:01:15.000
page-1 0 2025-04-12T10:00:00.000 2025-04-12T10:01:00.000
page-2 0 2025-04-12T10:00:00.000 2025-04-12T10:01:00.000
page-3 0 2025-04-12T10:00:00.000 2025-04-12T10:01:00.000
...
offset index for column ts:
offset compressed size first row index
page-0 15579636 799 0
page-1 15580435 206 20000
page-2 15580641 211 40000
page-3 15580852 222 60000
...
column index for column value:
Boundary order: UNORDERED
null count min max
page-0 0 1.0 9.71663529025E11
page-1 0 1.0 4.515E11
page-2 0 0.666666666667 2.91880144088E11
page-3 0 1.0 6.48308164166E11
...
offset index for column value:
offset compressed size first row index
page-0 2716801 35079 0
page-1 2751880 37579 20000
page-2 2789459 37277 40000
page-3 2826736 37638 60000
...
- Bloom Filer
对一些不重复值较少的列,利用字典编码可以实现查询时谓词下推,过滤掉不需要读取的 page,但如果不重复值较多会导致字典编码在存储上开销很大,因此引入 Bloom Filter 来解决这种情况下的过滤问题。
2.1.3 Footer
- FileMetaData
struct FileMetaData {
/** Version of this file **/
1: required i32 version
/** 定义数据表的格式,由一个单根节点的树构成,
* 按深度优先顺序打平保存到这个 list 里 **/
2: required list<SchemaElement> schema;
/** 一共包含的列数 **/
3: required i64 num_rows
/** 全部 RowGroups 的 MetaData **/
4: required list<RowGroup> row_groups
/** 可选的 key/value MetaData **/
5: optional list<KeyValue> key_value_metadata
/** 写这个 Parquet 文件的签名,格式为
* <Application> version <App Version> (build <App Build Hash>). */
6: optional string created_by
/** 每个 Column 里的值排 min max value 的顺序
* 由这里的 ColumnOrder 指定 */
7: optional list<ColumnOrder> column_orders;
/** 文件使用的加密算法,仅对 footer 为 plaintext 的文件有效 */
8: optional EncryptionAlgorithm encryption_algorithm
/** 对文件 footer 加密的 key 的 metadata */
9: optional binary footer_signing_key_metadata
}
/** RowGroup MetaData **/
struct RowGroup {
/** 每个 Column Chunk 的 Metadata,按 FileMetaData 里 schema 的顺序排列 */
1: required list<ColumnChunk> columns
/** RowGroup 下所有未压缩数据的总字节数 **/
2: required i64 total_byte_size
/** RowGroup 下总的数据行数 **/
3: required i64 num_rows
/** 如果设置了按该顺序对 RowGroup 下所有行排序,用来排序的列是所有列中的一部分 */
4: optional list<SortingColumn> sorting_columns
/** RowGroup 里第一个 Page 开始的地方和文件开头之间的 offset **/
5: optional i64 file_offset
/** RowGroup 下所有压缩数据的总字节数 **/
6: optional i64 total_compressed_size
/** RowGroup 的序号 **/
7: optional i16 ordinal
}
struct ColumnChunk {
/** ColumnChunk 所在的文件,如果为空表示与 FileMetaData 在同一个问题件 **/
1: optional string file_path
/** ColumnMetaData 开头到文件开头的 offset **/
2: required i64 file_offset
/** ColumnChunk 的列元信息 */
3: optional ColumnMetaData meta_data
/** OffsetIndex 在文件里的 offset **/
4: optional i64 offset_index_offset
/** OffsetIndex 的大小,单位字节 **/
5: optional i32 offset_index_length
/** ColumnIndex 在文件里的 offset **/
6: optional i64 column_index_offset
/** ColumnIndex 的大小,单位字节 **/
7: optional i32 column_index_length
/** 加密列的加密元信息 **/
8: optional ColumnCryptoMetaData crypto_metadata
/** ColumnChunk 列元数据加密后的结果 **/
9: optional binary encrypted_column_metadata
}
struct ColumnMetaData {
/** 列的类型 **/
1: required Type type
/** 该列的所有编码方式 **/
2: required list<Encoding> encodings
/** Path in schema **/
3: required list<string> path_in_schema
/** 压缩方式 **/
4: required CompressionCodec codec
/** 该列 value 的数量 **/
5: required i64 num_values
/** 该 ColumnChunk 所有未压缩的数据大小 (包括 headers) **/
6: required i64 total_uncompressed_size
/** 该 ColumnChunk 所有压缩的数据大小 (including the headers) **/
7: required i64 total_compressed_size
/** 可选的 key/value metadata **/
8: optional list<KeyValue> key_value_metadata
/** 从文件开头到第一个 data page 之间的 offset **/
9: required i64 data_page_offset
/** 从文件开头到 Footer 的 index page 之间的 offset **/
10: optional i64 index_page_offset
/** 从文件开头到唯一的一个 dictionary page 之间的 offset **/
11: optional i64 dictionary_page_offset
/** 该 ColumnChunk 的列统计信息 */
12: optional Statistics statistics;
/** 该 ColumnChunk 下所有 page 用到的编码方式 **/
13: optional list<PageEncodingStats> encoding_stats;
/** 从文件开头到 bloom filter 的数据之间的 offset **/
14: optional i64 bloom_filter_offset;
/** bloom filter 数据的字节大小 **/
15: optional i32 bloom_filter_length;
/**
* Optional statistics to help estimate total memory when converted to in-memory
* representations. The histograms contained in these statistics can
* also be useful in some cases for more fine-grained nullability/list length
* filter pushdown.
*/
16: optional SizeStatistics size_statistics;
}