【Paimon】Paimon 表排序
Paimon (1.0)对 Bucket Unaware 的 Append Only Table 支持写入时排序以提升查询效率,同时对分 Bucket 的 Append Only Table和 Dynamic Bucket 的 Primary Key Table ,提供了异步的 Sort Compact 支持。
排序之后的表在同一 Partition(或者同一 Bucket,取决于表类型) 下的数据会更有序地分布在各数据文件中,查询时利用有序性排除掉不需要读取的文件以减少 IO 开销,从而提升查询效率。这和在数据文件的 Metadata 里存储每一列的统计信息(Min/Max等)来实现 Data Skipping 是同样的原理。
1. Data Clustering
假设有一张表包含 A - C 3 个列,现将这张表水平拆为 125 张子表。
1.1 Linear Sorting
Linear Sorting 即是按 A B C 三列对表里的数据逐次排序,然后把数据按顺序拆分到各个子表中。
拆分完之后如果想查找 A = ai, B = bi, C = ci 的数据,则可以按顺序先找到 A = ai 所包含的子表,再在这些子表中找到 B = bi 所包含的子表 … 以此类推不断缩小查找范围。但如果查询条件是 B = bi, C = ci 则这样的划分就不再有用,因为失去 A 的有序性,包含 B = bi 和 C = ci 的子表大大增加,即关系数据库中常见的最左匹配原则。
1.2 多维度 Order Clustering
如果把 A B C 列按顺序划分为 5 个范围区间(a1…a5, b1…b5, c1…c5),每个区间任意组合得到 5 * 5 * 5 = 125 个区间,每个区间对应一张子表。这样在查询 B = bi, C = ci 的数据时,假设 bi 处于 b2 区间,ci 处于 c3 区间,则可以只用查找 [a1 b2 c3] [a2 b2 c3] … [a5 b2 c3] 这个五个区间对应的子表,相比 Linear Sorting 划分减少了查询范围。
这样的划分的本质是把每个维度里 value 较相近的数据放到同一个子表,降低单个维度的分散。换一种说法是把多个维度映射到一维,然后在这一维度里做划分。
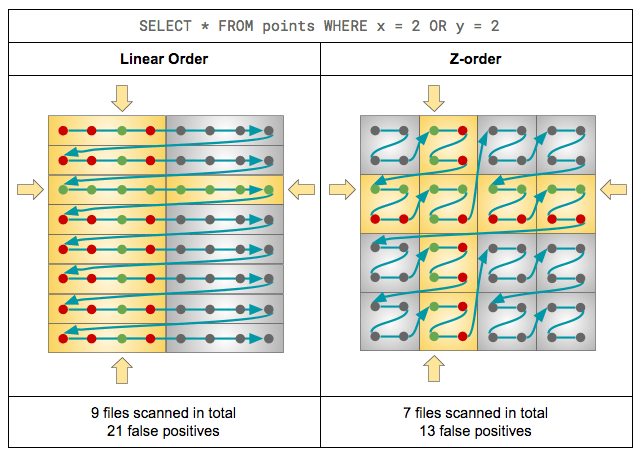
如 Databricks 文章里提供的这张图片所示,虽然两个维度都划分了一共 16 个区间,但划分方式的不同也会导致查询效率的差异。
- Z-Order Curve

Z-Order Curve 在多个有序维度里从小到大依次按 左上 右上 左下 右下 的顺序将多个维度串联成线,由小的 Z 组合成更大的 Z 并不断迭代直到占满整个多维空间。每个 Z 构成一个子空间,在这个子空间里最大空间距离(标识各维度范围的平均情况)更小。 - Hilbert Curve

Hilbert Curve 如上图所示,每一阶都由 4 个前一阶组成,其中左下和右下分别向右和向左旋转 90 度,再用直线按 左下 左上 右上 右下 的顺序连起来。

与 Z-Order Curve 相比 Hilbert Curve 中相邻数据点之间的距离始终保持相同,这是否能说明 Hilbert Curve 比 Z-Order 在各维度上的分散更小?需要进一步确认。
2. Paimon 的代码实现
如前所述, 对Bucket Unaware 的 Append Only Table排序写入在 org.apache.paimon.flink.sink.FlinkSinkBuilder 实现;对分 Bucket 的 Append Only Table和 Dynamic Bucket 的 Primary Key Table 做异步的 Sort Compact 在 org.apache.paimon.flink.action.SortCompactAction 实现。两处都是通过对数据流做排序,根据配置由不同的 org.apache.paimon.flink.sorter.TableSorter 实现具体的排序逻辑,包括:
- OrderSorter:按字符顺序对指定列做排序
- ZorderSorter:按 Z-Order 排序
- HilbertSorter:按 Hilbert Order 排序
在这些 Sorter 中定义不同 sort key 的实现逻辑,最终排序的执行交由 SortUtils 实现。
2.1 sort key 的生成
2.1 排序的实现
SortUtils (org.apache.paimon.flink.sorter.SortUtils#sortStreamByKey)
public static <KEY> DataStream<RowData> sortStreamByKey(
final DataStream<RowData> inputStream, // 输入数据流
final FileStoreTable table, // 数据表的信息
final RowType sortKeyType, // sort key 的 RowType,这里可能是多个列组成
final TypeInformation<KEY> keyTypeInformation, // sort key 的 TypeInformation
final SerializableSupplier<Comparator<KEY>> shuffleKeyComparator, // 提供 sort key 对比方法的 supplier
final KeyAbstract<KEY> shuffleKeyAbstract, // 从输入数据中提取 sort key
final ShuffleKeyConvertor<KEY> convertor, // 将 sort key 转换为 InternalRow 的方法
final TableSortInfo tableSortInfo) // 排序配置
{
final RowType valueRowType = table.rowType();
CoreOptions options = table.coreOptions();
final int sinkParallelism = tableSortInfo.getSinkParallelism();
final int localSampleSize = tableSortInfo.getLocalSampleSize();
final int globalSampleSize = tableSortInfo.getGlobalSampleSize();
final int rangeNum = tableSortInfo.getRangeNumber();
int keyFieldCount = sortKeyType.getFieldCount();
int valueFieldCount = valueRowType.getFieldCount();
final int[] valueProjectionMap = new int[valueFieldCount];
for (int i = 0; i < valueFieldCount; i++) {
valueProjectionMap[i] = i + keyFieldCount;
}
// 把作为 sort key 的列和数据表原本的列拼接成新的 RowType
List<DataField> keyFields = sortKeyType.getFields();
List<DataField> dataFields = valueRowType.getFields();
List<DataField> fields = new ArrayList<>();
fields.addAll(keyFields);
fields.addAll(dataFields);
final RowType longRowType = new RowType(fields);
final InternalTypeInfo<InternalRow> internalRowType =
InternalTypeInfo.fromRowType(longRowType);
// 把输入的 RowData 转换成 sort key 和 RowData 组成的 Tuple
DataStream<Tuple2<KEY, RowData>> inputWithKey =
inputStream
.map(
new RichMapFunction<RowData, Tuple2<KEY, RowData>>() {
public void open(OpenContext openContext) throws Exception {
open(new Configuration());
}
public void open(Configuration parameters) throws Exception {
shuffleKeyAbstract.open();
}
@Override
public Tuple2<KEY, RowData> map(RowData value) {
// 提取 sort key 并组合成 Tuple
return Tuple2.of(shuffleKeyAbstract.apply(value), value);
}
},
new TupleTypeInfo<>(keyTypeInformation, inputStream.getType()))
.setParallelism(inputStream.getParallelism());
// 根据 sort key 做 Range Shuffle,将属于同一 cluster 的数据分发到对应的 sink task,
// 后面写到同一个数据文件中
DataStream<Tuple2<KEY, RowData>> rangeShuffleResult =
RangeShuffle.rangeShuffleByKey(
inputWithKey,
shuffleKeyComparator,
keyTypeInformation,
localSampleSize,
globalSampleSize,
rangeNum,
sinkParallelism,
valueRowType,
options.sortBySize());
// 如果 sort-in-cluster 配置为 true,则进一步在各 cluster 里做排序
if (tableSortInfo.isSortInCluster()) {
return rangeShuffleResult
.map(
// 将 sort key 和 输入的 RowData 转换成 JoinedRow
a -> new JoinedRow(convertor.apply(a.f0), new FlinkRowWrapper(a.f1)),
internalRowType)
.setParallelism(sinkParallelism)
// 用 SortOperator 做进一步排序
.transform(
"LOCAL SORT",
internalRowType,
new SortOperator(
sortKeyType,
longRowType,
options.writeBufferSize(),
options.pageSize(),
options.localSortMaxNumFileHandles(),
options.spillCompressOptions(),
sinkParallelism,
options.writeBufferSpillDiskSize(),
options.sequenceFieldSortOrderIsAscending()))
.setParallelism(sinkParallelism)
// 去掉 sort key,只保留数据表的列
.map(
new RichMapFunction<InternalRow, InternalRow>() {
private transient KeyProjectedRow keyProjectedRow;
public void open(OpenContext openContext) {
open(new Configuration());
}
public void open(Configuration parameters) {
keyProjectedRow = new KeyProjectedRow(valueProjectionMap);
}
@Override
public InternalRow map(InternalRow value) {
return keyProjectedRow.replaceRow(value);
}
},
InternalTypeInfo.fromRowType(valueRowType))
.setParallelism(sinkParallelism)
// 从 InternalRow 转换回 FlinkRowData
.map(FlinkRowData::new, inputStream.getType())
.setParallelism(sinkParallelism);
} else {
// 如果不做 sort-in-cluster,则直接去掉 sort key
return rangeShuffleResult
.transform("REMOVE KEY", inputStream.getType(), new RemoveKeyOperator<>())
.setParallelism(sinkParallelism);
}
}
RangeShuffle 按照 sort key 把数据划分到对应的子文件
public static <T> DataStream<Tuple2<T, RowData>> rangeShuffleByKey(
DataStream<Tuple2<T, RowData>> inputDataStream,
SerializableSupplier<Comparator<T>> keyComparator,
TypeInformation<T> keyTypeInformation,
int localSampleSize,
int globalSampleSize,
int rangeNum,
int outParallelism,
RowType valueRowType,
boolean isSortBySize) {
Transformation<Tuple2<T, RowData>> input = inputDataStream.getTransformation();
// 把 sort key 和 RowData 组成的输入流转换成 sort key 和 RowData size 组成的数据流
OneInputTransformation<Tuple2<T, RowData>, Tuple2<T, Integer>> keyInput =
new OneInputTransformation<>(
input,
"ABSTRACT KEY AND SIZE",
new StreamMap<>(new KeyAndSizeExtractor<>(valueRowType, isSortBySize)),
new TupleTypeInfo<>(keyTypeInformation, BasicTypeInfo.INT_TYPE_INFO),
input.getParallelism());
// 1. 上一步输出的数据流由 Sampler 对其进行分区采样,分区的数量是数据流的并行度,
// 采样逻辑是随机取 K 个 record 输出, K 由 localSampleSize 确定
// PS. 不明白这里为什么要把 LocalSampleOperator 的输出从 Tuple2<Double, Tuple2<T, Integer>>
// 改到 Tuple3<Double, T, Integer>,然后在下一步 GlobalSampleOperator 里又转回 Tuple2<Double, Tuple2<T, Integer>>
OneInputTransformation<Tuple2<T, Integer>, Tuple3<Double, T, Integer>> localSample =
new OneInputTransformation<>(
keyInput,
"LOCAL SAMPLE",
new LocalSampleOperator<>(localSampleSize),
new TupleTypeInfo<>(
BasicTypeInfo.DOUBLE_TYPE_INFO,
keyTypeInformation,
BasicTypeInfo.INT_TYPE_INFO),
keyInput.getParallelism());
// 2. 上一步输出的数据流做全局抽样,取 K 个 record,K 由 globalSampleSize 确定,用 keyComparator
// 抽样后的 records 排序,在 allocateRangeBaseSize 方法中根据这些 records 划分每个 range 在 key
// 的一维空间中的边界
OneInputTransformation<Tuple3<Double, T, Integer>, List<T>> sampleAndHistogram =
new OneInputTransformation<>(
localSample,
"GLOBAL SAMPLE",
new GlobalSampleOperator<>(globalSampleSize, keyComparator, rangeNum),
new ListTypeInfo<>(keyTypeInformation),
1);
// 3. range 的边界信息作为广播流和数据流合并,在 AssignRangeIndexOperator 中用二分查找确定每个 record
// 所属的 range,将 range 的 index 作为 record 的 partition id 一起输出
TwoInputTransformation<List<T>, Tuple2<T, RowData>, Tuple2<Integer, Tuple2<T, RowData>>>
preparePartition =
new TwoInputTransformation<>(
new PartitionTransformation<>(
sampleAndHistogram,
new BroadcastPartitioner<>(),
StreamExchangeMode.BATCH),
new PartitionTransformation<>(
input,
new ForwardPartitioner<>(),
StreamExchangeMode.BATCH),
"ASSIGN RANGE INDEX",
new AssignRangeIndexOperator<>(keyComparator),
new TupleTypeInfo<>(
BasicTypeInfo.INT_TYPE_INFO, input.getOutputType()),
input.getParallelism());
// 4. 根据 partition id 将 record shuffle 到对应的 output sink,并去掉 partition id
return new DataStream<>(
inputDataStream.getExecutionEnvironment(),
new OneInputTransformation<>(
new PartitionTransformation<>(
preparePartition,
new CustomPartitionerWrapper<>(
new AssignRangeIndexOperator.RangePartitioner(rangeNum),
new AssignRangeIndexOperator.Tuple2KeySelector<>()),
StreamExchangeMode.BATCH),
"REMOVE RANGE INDEX",
new RemoveRangeIndexOperator<>(),
input.getOutputType(),
outParallelism));
}
// 根据抽样数据计算每个 range 的范围计算逻辑
static <T> T[] allocateRangeBaseSize(List<Tuple2<T, Integer>> sampledData, int rangesNum) {
int sampeNum = sampledData.size();
int boundarySize = rangesNum - 1;
@SuppressWarnings("unchecked")
T[] boundaries = (T[]) new Object[boundarySize];
if (!sampledData.isEmpty()) {
// 所有抽样数据 RowData size 总和
long restSize = sampledData.stream().mapToLong(t -> (long) t.f1).sum();
// 总 size / 总 range 数,当前 range 的平均 size 大小
double stepRange = restSize / (double) rangesNum;
// currentWeight 记录当前 range 的 size
int currentWeight = 0;
int index = 0;
for (int i = 0; i < boundarySize; i++) {
while (currentWeight < stepRange && index < sampeNum) {
// 将 range 的 boundary 更新为最新一个抽样数据的 sort key
boundaries[i] = sampledData.get(Math.min(index, sampeNum - 1)).f0;
int sampleWeight = sampledData.get(index++).f1;
// 累加当前 range 的 size
currentWeight += sampleWeight;
// 更新剩余的 size 总量
restSize -= sampleWeight;
}
currentWeight = 0;
// 更新下一个 range 的平均 size 大小
stepRange = restSize / (double) (rangesNum - i - 1);
}
}
// 如果前面有 range 的 boundary 没有更新,则设置为最后一个抽样数据的 sort key
for (int i = 0; i < boundarySize; i++) {
if (boundaries[i] == null) {
boundaries[i] = sampledData.get(sampeNum - 1).f0;
}
}
return boundaries;
}
3. 测试
4. 相关文档
Data Clustering 介绍:
https://en.wikipedia.org/wiki/Z-order_curve
https://www.databricks.com/blog/2018/07/31/processing-petabytes-of-data-in-seconds-with-databricks-delta.html
https://zhuanlan.zhihu.com/p/696053812